This is a developmental version, just
to show what's in progress. Most everything is there and working, but it
might freeze or crash (unlikely, but if so, I
want to know about it, what you were doing). Several files have changed
since the previous upload, so if you downloaded a previous version, please
discard the whole folder and replace it with this new download. Hopefully
I will make the documentation friendlier and more complete in a future
upload. I know how to do that, but it's a lot of work, and I've
been concentrating my effort on just getting it working. For more insight
on how it does what it's doing, see Details on How
BibleTrans Works.
Please read these instructions. This is not an overly friendly program (yet :-)
1. Down this file: BTdemo.zip
2. Unpack the zip file. It won't run properly inside the zip. You need the whole folder unpacked on your hard drive, preferably in its own folder.
3. Start up the BTrans.exe program. [It will take a few minutes building tree files in its folder, then quits. This step is no longer necessary]
4. [Restart it.] Normally you should see a progress dialog "Loading English..." If you have been running a previous version of BibleTrans, it might fail to load automatically. If you don't see it, choose Open from the File menu and open the English.txt (grammar) file to get it loaded. There is a slight delay after importing a large grammar like this, before anything else works, up to a minute on my very slow Win95 system. Sometimes it fails to load (gives an error report), but quitting and restarting and trying again usually works.
5. After a few seconds the "BibleTrans Demo" window should have a "Translation Demo" button, which you can click to set up the John 3:16 tree for translation. If the button doesn't depress (it happens to me in Win95 right after loading the grammar file), wait a minute or two and try again. If it still doesn't depress, quit and restart BibleTrans again.
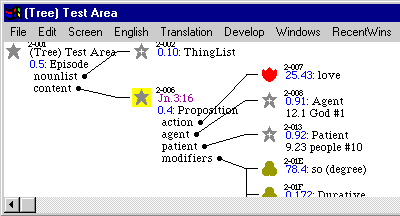
Now you should see a window showing a portion of the John 3:16 tree, like this:
The yellow square is the selected node. That's the tree part that will be translated. This picture shows the whole verse selected. There will be another blank window where the translation will be shown.
6. Choose "Translate" from the Translation menu. After a slight delay, the menu title will change to "Translate.." and then (after a longer delay) to "Translating" and then back again when it finishes. The output window should start showing text.
I had some difficulty in Win95 with it opening one or more "Lex Rule" windows for me to fill in. I think this problem is fixed, but if it happens to you, quit and restart BibleTrans, then reload the English.txt (grammar) file from the File menu and try again. I've heard of memory problems in Win95, and I did not have this problem in WinXP. Quitting and restarting seems to help a lot.
7. If the output window is not showing, you can choose "Jn.3:16" from the Translation menu to view the translated text in its window. You can "Save" (from the File menu) the translation as a text file, or copy-paste or drag it into a word processor program window.
8. Right-click one of the red verb or blue noun icons in the tree window (2-click Thing icon to get to the noun) to select the lexical ("Lex") rule for that concept, which you can then modify to whatever you like, and then run the translation again to see how it changes. You can also change the tree, see the blue "Building the Database" link in the Welcome window.
You can always open the English.txt file from the File menu to get back to this working version of the English grammar. Clicking the "Translation Demo" button reloads the tree.
This is not a cardboard mock-up, it really is translating the tree concepts you see into English.
This grammar also works for the first chapter of Philippians. Right-click the "Php.1:1" link in the Welcome page to open the tree window of those two verses, then click the 6-point teal star with the verse number to select it. When you translate it, it will add another item to the Translation menu so you can look at the output. The rest of Philippians should be coming "Real Soon Now" but chapter 2 is pretty tricky.
9. In the "BibleTrans Demo" window there is a link to "English Grammar Step by Step" which explains in excruciating detail how I wrote the English language grammar, so you could write your own grammar to translate the trees into any language you like.
Also in this download file is a complete Greek New Testament (click "Analytical Greek New Testament Table of Contents" link in Welcome window) and a fragmentary "fake" Louw&Nida lexicon (see "Louw&Nida ToC" link). The Luke trees have numerous uncorrected problems.
Also included, by permission from www.bible.org,
is the New Testament from the NETBible![]() with full critical notes (Copyright
with full critical notes (Copyright![]() 1996 Biblical Studies Press). NETBible
1996 Biblical Studies Press). NETBible![]() is a registered trademark of Biblical Studies Press.
is a registered trademark of Biblical Studies Press.
This document is current as of 2014 June 4
I also have an early (paid-for) copy of GramCord and the Greek text exported from the Translator's Workplace CD database, which were compared for non-textual issues like capitalization, punctuation, and the like, but did not contribute to the Greek text itself. Where two or more independent sources agreed on the punctuation, I assumed that it constituted common knowledge and therefore inserted it into my text. The result is that some punctuation got left out.
One of the internet sources tagged each Greek word with its Strongs number, and I was able to infer in most cases a "lemma" (the uninflected lexical form of the Greek word) from its Strongs dictionary entry. This I compared against the TW and GC databases for the same word and used it as the lemma in my text when there was agreement, which again I took for public knowledge. Some words in my text show no lemma, because I did not find agreement on those words. The fact that there were a significant number of disagreements proves that these are indeed independent sources. These same three sources each provided a parse code for each word in the text. The encoding was different in each case, and there were some disagreements, but I was able to write a program that looked for conceptual agreement and tagged my own text with the agreed parse (although my own codes are different in form from theirs, the information is the same). These parse codes represent a significant intellectual effort on the part of the people who prepared the respective texts, but USA copyright law protects only the expression of ideas, not the ideas themselves. Where the ideas (how to parse a particular word, or how to spell its dictionary form) are the same in two or more sources, I have not copied from any one source but only provided a new expression of the same common-knowledge idea expressed in both places.
The English "gloss" words used to translate the individual Greek words are a similar derived effort. Many of the Greek words have been assigned a Louw&Nida tag in my software, either by me or else by a person on my payroll, so I own that information. These L&N concepts in turn were given short English glosses suitable for displaying them in the BibleTrans tree representation. The glosses were generally inspired by the L&N dictionary definitions, but not often the same words (which tend to be too long for convenient display), so again, I own those glosses. Where we have single L&N tags on the Greek text and my own glosses for those concepts, I used those glosses in displaying the text. My software uses a variety of heuristics to assign L&N tags or collections of possible tags to the Greek text, but human judgment is required to make the final definition. In some cases, such as proper names, there is really only one choice.
Where I do not have a single L&N tag and a tree gloss for it, I used the Strongs number to pick out a short definition from Strong's dictionary. This dictionary is in the public domain, and I obtained an electronic copy on CD from a company that paid people to type it in manually. I respect their effort, and although it would be legal for me to copy and distribute the whole dictionary, I won't. Instead I wrote a program to scan through the dictionary and pick out the English definition words. Because the text was manually prepared from the printed book, there is a great variability in the data format, which my program could not adequately overcome. Furthermore, Mr.Strong himself was not very consistent in his format. So my program reviews each dictionary entry and does its best at picking out the definition words, and then I manually selected one of them as my gloss for that Greek word. Sometimes the formatting was so bad I had to retype the meaning from the words that were there. In one case it was completely missing, and I had to infer it from the Greek (which I know reasonably well). Most of the definitions offer several different English words; I tried to select the word or phrase that best and briefly captured the composite sense or base meaning (which was often explicitly stated). Sometimes the same English word showed up twice, and I usually chose that -- unless (most often in the case of proper names, where Strong favored archaic or transliterated Greek spelling) there was a more common form of the name also in the list. When there was little difference in meaning, or if I did not know the word(s) myself, the choices were somewhat arbitrary. I have several other Greek dictionaries, but I tried not to look in any other source while doing this. These glosses now represent my own edition of Strongs, and are therefore free for me to use. The Strongs words are only a temporary stop-gap, until I have all the Greek words tagged with L&N numbers, and English glosses for those concepts.
The licensed version of BibleTrans (available, ask me) uses the Friberg parse codes (under license by permission of Timothy Friberg) applied to the modern Greek text by permission of the German Bible Society (which owns the copyright to it), and I must pay a royalty for every copy I distribute. I also have permission from the American Bible Society to distribute (again for a royalty) the actual Louw&Nida lexicon, so I use their definitions instead of Strong's in that (licensed) version when possible. I would like to license an existing published interlinear English text, but I do not know who owns the rights (somebody please tell me).
The United Bible Society edition of the Greek New Testament has English
section headers, which are licensed with the Greek text, and included in
my licensed version. For the public-domain edition available here I have
extracted the section headers and paragraph breaks from the 1901 American
Standard Version of the Bible. These do not match the UBS version, and
no attempt has been made to reconcile them. Since display page breaks are
between sections, there will be some discrepancies between the download
version and the licensed version. However this is only in the Greek text;
the propositionalized tree representation of the text, which BibleTrans
uses for its translation, is manually prepared in the judgment of the scholar(s)
doing that work, and may or may not reflect either or both of those sources.
The public-domain Greek text is available for download from:
http://www-user.uni-bremen.de/~wie/GNT/The same nominal text with Strongs numbers and parse codes is available at:
http://www.olivetree.com/cgi-bin/EnglishBible.htmA number of public-domain Bible reference materials are available on CD from Ages Software:
http://www.ageslibrary.com